В прошлом мы рассказывали о технологии одновременной многопоточности (Simultaneous Multi-Threading - SMT), которая применяется в процессорах Intel. И хотя первоначально она создавалась под кодовым именем "технология Джексона" (Jackson Technology) как возможный, вероятный вариант, Intel официально анонсировала свою технологию на форуме IDF прошлой осенью. Кодовое имя Jackson было заменено более подходящим Hyper-Threading. Итак, для того чтобы разобраться, как работает новая технология, нам нужны кое-какие первоначальные знания. А именно, нам нужно знать, что такое поток, как выполняются эти потоки. Почему работает приложение? Как процессор узнает, какие операции и над какими данными он должен совершать? Вся эта информация содержится в откомпилированном коде выполняемого приложения. И как только приложение получает от пользователя какую-либо команду, какие-либо данные, – процессору сразу же отправляются потоки, в результате чего он и выполняет то, что должен выполнить в ответ на запрос пользователя. С точки зрения процессора, поток – это набор инструкций, которые необходимо выполнить. Когда в вас попадает снаряд в Quake III Arena, или когда вы открываете документ Microsoft Word, процессору посылается определенный набор инструкций, которые он должен выполнить.
Процессор точно знает, где брать эти инструкции. Для этой цели предназначен редко упоминаемый регистр, называемый счетчиком команд (Program Counter, PC). Этот регистр указывает на место в памяти, где хранится следующая для выполнения команда. Когда поток отправляется на процессор, адрес памяти потока загружается в этот счетчик команд, чтобы процессор знал, с какого именно места нужно начать выполнение. После каждой инструкции значение этого регистра увеличивается. Весь этот процесс выполняется до завершения потока. По окончании выполнения потока, в счетчик команд заносится адрес следующей инструкции, которую нужно выполнить. Потоки могут прерывать друг друга, при этом процессор запоминает значение счетчика команд в стеке и загружает в счетчик новое значение. Но ограничение в этом процессе все равно существует – в каждую единицу времени можно выполнять лишь один поток.
Существует общеизвестный способ решения данной проблемы. Заключается он в использовании двух процессоров – если один процессор в каждый момент времени может выполнять один поток, то два процессора за ту же единицу времени могут выполнять уже два потока. Отметим, что этот способ не идеален. При нем возникает множество других проблем. С некоторыми, вы уже, вероятно, знакомы. Во-первых, несколько процессоров всегда дороже, чем один. Во-вторых, управлять двумя процессорами тоже не так-то просто. Кроме того, не стоит забывать о разделении ресурсов между процессорами. Например, до появления чипсета AMD 760MP, все x86 платформы с поддержкой многопроцессорности разделяли всю пропускную способность системной шины между всеми имеющимися процессорами. Но основной недостаток в другом – для такой работы и приложения, и сама операционная система должны поддерживать многопроцессорность. Способность распределить выполнение нескольких потоков по ресурсам компьютера часто называют многопоточностью. При этом и операционная система должна поддерживать многопоточность. Приложения также должны поддерживать многопоточность, чтобы максимально эффективно использовать ресурсы компьютера. Не забывайте об этом, когда мы будем рассматривать ещё один подход решения проблемы многопоточности, новую технологию Hyper-Threading от Intel.
Производительности всегда мало
Об эффективности всегда много говорят. И не только в корпоративном окружении, в каких-то серьезных проектах, но и в повседневной жизни. Говорят, homo sapiens лишь частично задействуют возможности своего мозга. То же самое относится и к процессорам современных компьютеров.
Взять, к примеру, Pentium 4. Процессор обладает, в общей сложности, семью исполнительными устройствами, два из которых могут работать с удвоенной скоростью – две операции (микрооперации) за такт. Но в любом случае, вы бы не нашли программы, которая смогла бы заполнить инструкциями все эти устройства. Обычные программы обходятся несложными целочисленными вычислениями, да несколькими операциями загрузки и хранения данных, а операции с плавающей точкой остаются в стороне. Другие же программы (например, Maya) главным образом загружают работой устройства для операций с плавающей точкой.
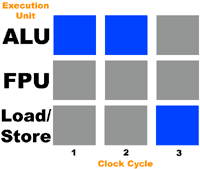
Чтобы проиллюстрировать ситуацию, давайте вообразим себе процессор с тремя исполнительными устройствами: арифметико-логическим (целочисленным – ALU), устройством для работы с плавающей точкой (FPU), и устройством загрузки/хранения (для записи и чтения данных из памяти). Кроме того, предположим, что наш процессор может выполнять любую операцию за один такт и может распределять операции по всем трем устройствам одновременно. Давайте представим, что к этому процессору на выполнение отправляется поток из следующих инструкций:
1+1
10+1
Сохранить предыдущий результат
Рисунок ниже иллюстрирует уровень загруженности исполнительных устройств (серым цветом обозначается незадействованное устройство, синим – работающее устройство):