Углубляемся в технологию
Помните те два потока из предыдущих примеров? Давайте на этот раз предположим, что наш процессор оснащен Hyper-Threading. Посмотрим, что получится, если мы попытаемся одновременно выполнить эти два потока:
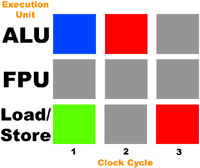
Как и ранее, синие прямоугольники указывают на выполнение инструкции первого потока, а зеленые - на выполнение инструкции второго потока. Серые прямоугольники показывают незадействованные исполнительные устройства, а красные - конфликт, когда на одно устройство пришло сразу две разных инструкции из разных потоков.
Итак, что же мы видим? Параллелизм на уровне потоков дал сбой – исполнительные устройства стали использоваться ещё менее эффективно. Вместо параллельного выполнения потоков, процессор выполняет их медленнее, чем если бы он выполнял их без Hyper-Threading. Причина довольно проста. Мы пытались одновременно выполнить сразу два очень похожих потока. Ведь оба они состоят из операций по загрузке/сохранению и операций сложения. Если бы мы параллельно запускали "целочисленное" приложение и приложение, работающее с плавающей точкой, мы бы оказались куда в лучшей ситуации. Как видим, эффективность Hyper-Threading сильно зависит от вида нагрузки на ПК.
В настоящий момент, большинство пользователей ПК используют свой компьютер примерно так, как описано в нашем примере. Процессор выполняет множество очень схожих операций. К сожалению, когда дело доходит до однотипных операций, возникают дополнительные сложности с управлением. Случаются ситуации, когда исполнительных устройств нужного типа уже не осталось, а инструкций, как назло, вдвое больше обычного. В большинстве случаев, если бы процессоры домашних компьютеров использовали технологию Hyper-Threading, то производительность бы от этого не увеличилась, а может быть, даже снизилась на 0-10%.
На рабочих же станциях возможностей для увеличения производительности у Hyper-Threading больше. Но с другой стороны, все зависит от конкретного использования компьютера. Рабочая станция может означать как high-end компьютер для обработки 3D графики, так и просто сильно нагруженный компьютер.
Наибольший же прирост в производительности от использования Hyper-Threading наблюдается в серверных приложениях. Главным образом это объясняется широким разнообразием посылаемых процессору операций. Сервер баз данных, использующих транзакции, может работать на 20-30% быстрее при включенной опции Hyper-Threading. Чуть меньший прирост производительности наблюдается на веб-серверах и в других сферах.
Максимум эффективности от Hyper-Threading
Вы думаете, Intel разработала Hyper-Threading только лишь для своей линейки серверных процессоров? Конечно же, нет. Если бы это было так, они бы не стали впустую тратить место на кристалле других своих процессоров. По сути, архитектура NetBurst, использующаяся в Pentium 4 и Xeon, как нельзя лучше подходит для ядра с поддержкой одновременной многопоточности. Давайте ещё раз представим себе процессор. На этот раз в нем будет ещё одно исполнительное устройство – второе целочисленное устройство. Посмотрим, что случится, если потоки будут выполняться обоими устройствами:
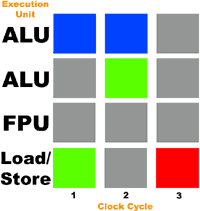
С использованием второго целочисленного устройства, единственный конфликт случился только на последней операции. Наш теоретический процессор в чем-то похож на Pentium 4. В нем имеется целых три целочисленных устройства (два ALU и одно медленное целочисленное устройство для циклических сдвигов). А что ещё более важно, оба целочисленных устройства Pentium 4 способны работать с двойной скоростью – выполнять по две микрооперации за такт. А это, в свою очередь, означает, что любое из этих двух целочисленных устройств Pentium 4/Xeon могло выполнить те две операции сложения из разных потоков за один такт.
Но это не решает нашей проблемы. Было бы мало смысла просто добавлять в процессор дополнительные исполнительные устройства с целью увеличения производительности от использования Hyper-Threading. С точки зрения занимаемого на кремнии пространства это было бы крайне дорого. Вместо этого, Intel предложила разработчикам оптимизировать программы под Hyper-Threading.
Используя инструкцию HALT, можно приостановить работу одного из логических процессоров, и тем самым увеличить производительность приложений, которые не выигрывают от Hyper-Threading. Итак, приложение не станет работать медленнее, вместо этого один из логических процессоров будет остановлен, и система будет работать на одном логическом процессоре – производительность будет такой же, что и на однопроцессорных компьютерах. Затем, когда приложение сочтет, что от Hyper-Threading оно выиграет в производительности, второй логический процессор просто возобновит свою работу.
На веб-сайте Intel имеется презентация, описывающая, как именно необходимо программировать, чтобы извлечь из Hyper-Threading максимум выгоды.